tree-sitter is a parser generator. You can use it to parse source code which is the first step of static analysis. For example, GitHub uses it to highlight code, code navigation, and also in CodeQL extractors.
TL;DR: Queries are great for capturing text from code. But to extract anything moderately structured we need to traverse the syntax tree.
And, yes, the title is based on Doom Episode 1 Knee Deep in the Dead. I love the title (and the game), because it lets me relive my edgy days.
Intro and Literature Review
tree-sitter has a simple, but powerful query language. Unfortunately, there are only a few tutorials out there. Some good starting points:
- Pattern Matching with Queries from the official docs.
- Tips for using tree sitter queries from Bearer.
- Lightweight linting with tree-sitter from DeepSource.
A query is a path in the tree. Always keep this in mind when creating queries. If a path in the query doesn't match, there will be no results. There are no partial captures.
I will be starting with the playground at: https://tree-sitter.github.io/tree-sitter/7-playground.html. Click on any item in the tree at the bottom to see it highlighted in the code and vice versa.
Update Sep 2025: The tree-sitter playground has moved since writing the blog and I've updated the link. The screenshots are from the old playground and might not look like the new one.
Most playground examples use @capture, but the name is freeform (and can even
contain .). The capture gets a color and its matching captures are highlighted
in code with the same color. Nifty!
If you check the Log box, the logs appear in the browser console in DevTools.
Basic Example
I am gonna use this code in the playground. We really don't care if the code compiles; we're just interested if tree-sitter can parse it.
package main
func main() {
out, err := Deserialize(a, b)
if err != nil {
panic(err)
}
// Do something with out.
}
Use the tree to see the name of nodes. Note these names are different between
languages. E.g., this is the tree for the main file and package main.
source_file
package_clause
package_identifier
(package_clause) @capture returns that whole line. See how package main is
highlighted because of @capture.
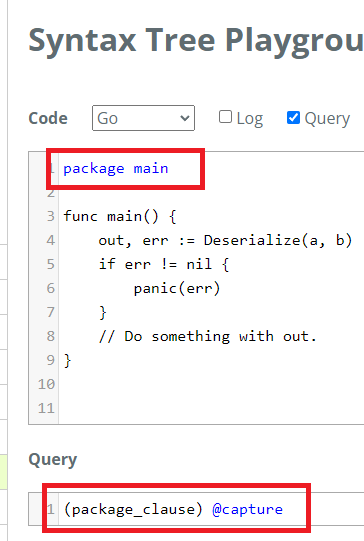
We can only capture using names highlighted in blue in the tree. These are "Named Nodes." From the docs:
The parenthesized syntax for writing nodes only applies to named nodes.
I think these are the ones in the node-types.json file in the language repo.
That file is very useful for static analysis. E.g., GitHub's CodeQL extractor
creates a database based on these files for each language
(source Code scanning and Ruby: turning source code into a queryable database).
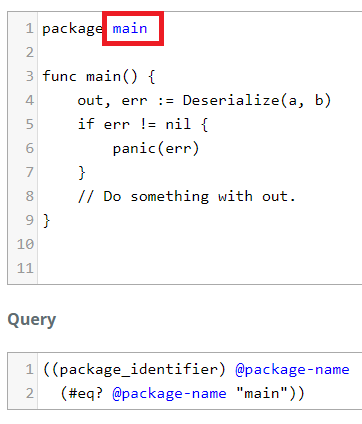
We could go deeper and only select main with (package_identifier) @capture.
But to only match where package name is main, we have to add a predicate (see
the Predicates section in the tutorial). The predicate here is essentially
if @package-name == "main".
((package_identifier) @package-name
(#eq? @package-name "main"))
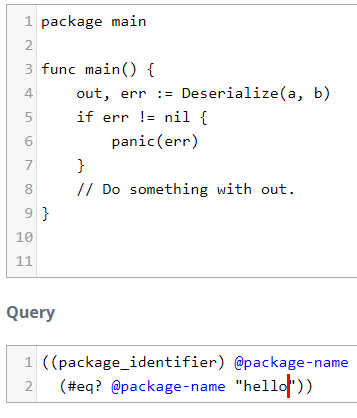
Change the string from main to hello to see how it's not highlighted anymore.
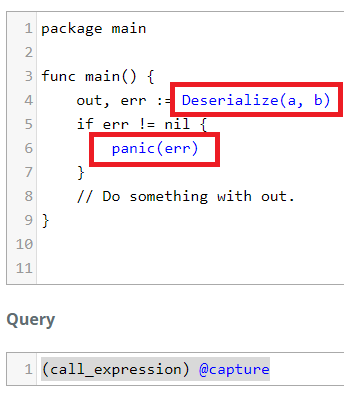
Similar query to capture function calls. The entire function line is considered
a short_var_declaration which is basically anytime we see a := .... We're
only interested in the function call which is a call_expression.
call_expression // Deserialize(a, b)
function: identifier // Deserialize
arguments: argument_list // (a, b)
identifier // a
identifier // b
(call_expression) @capture highlights both calls: Deserialize and panic.
But call_expression also includes the parameters. If we just want the function
names, we have to capture the function field for the call_expression node
and use a predicate. More about fields:
https://tree-sitter.github.io/tree-sitter/using-parsers#node-field-names.
Things get complicated pretty quickly, so we will capture function names first and then add the predicate.
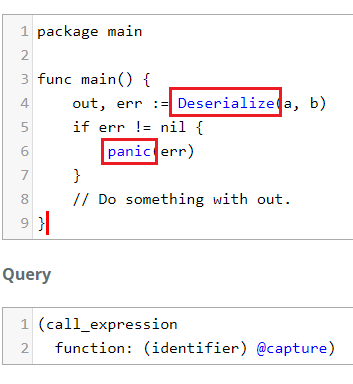
(call_expression
function: (identifier) @capture)
We start with call_expression, then we add the function field name. The
field is a child node of type identifier so we add it to our query's path to
capture it. Now we have captured only Deserialize and panic. This may look
like casting, but it's not. We're not casting the name of the function into an
identifier. We're looking for code where the value of the function field is
an identifier.
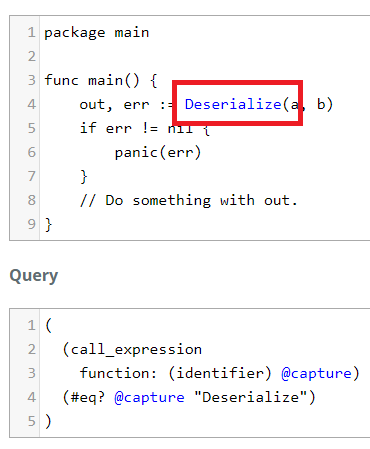
Now we wrap this in () and add our predicate for @capture.
(
(call_expression
function: (identifier) @capture)
(#eq? @capture "Deserialize")
)
Function Parameters
We can further expand this query and also include the types of function parameters.
This gives us a new challenge. The type (or _type in
node-types.json) is not always a type_identifier like the
return values.
{
"type": "_type",
"named": true,
"subtypes": [
{
"type": "_simple_type",
"named": true
},
{
"type": "parenthesized_type",
"named": true
}
]
},
We can see it more clearly in the tree-sitter-go/grammar.js file.
_type: $ => choice(
$._simple_type,
$.parenthesized_type,
),
parenthesized_type: $ => seq('(', $._type, ')'),
_simple_type: $ => choice(
prec.dynamic(-1, $._type_identifier),
$.generic_type,
$.qualified_type,
$.pointer_type,
$.struct_type,
$.interface_type,
$.array_type,
$.slice_type,
$.map_type,
$.channel_type,
$.function_type,
$.union_type,
$.negated_type,
),
Quick Solution
Trying to account for all of these types is a nightmare. So I just hand-waved it
with a wildcard node. It matches any node. I am using it
similar to the getText method in ANTLR (which is another useful
parser generator I have used in the past). That method returns the text that
matched that node which include everything in the node and its children.
So we're just gonna say, show me the text in the type:
(function_declaration
parameters: (parameter_list
(parameter_declaration
type: (_) @param-type))
)
This works for most things, but has two issues:
- We need to parse the type further if we want more granular information.
- That is a problem for future Parsia (like two hours into the future)!
- We will have issues with some common idiomatic Go stuff.
- Variadic parameters.
Variadic Function Parameters
Variadic functions like func test(a ...int) are another issue. A
parameter_list can contain both parameter_declaration and
variadic_parameter_declaration.
// func test(a, b int)
function_declaration
name: identifier
parameters: parameter_list // (a ...int)
variadic_parameter_declaration // a ...int
name: identifier // a
type: type_identifier // int
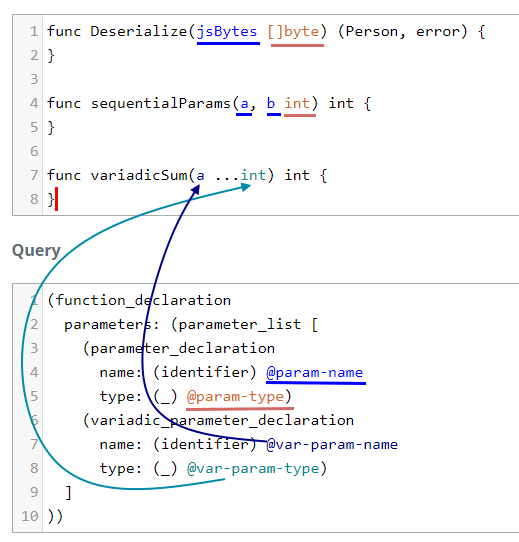
We can make our query better with Alternations. Alternations are
choices that appear between []. We're telling the query to match if it can
take any of the choices. In this case we are accounting for the two
parameter_declaration options.
Hint: When you see choice in the tree-sitter grammar, it's time for alternations.
(function_declaration
parameters: (parameter_list [
(parameter_declaration
name: (identifier) @param-name
type: (_) @param-type)
(variadic_parameter_declaration
name: (identifier) @var-param-name
type: (_) @var-param-type)
]
))
Simple Types
So we've fixed the variadic function issue, but the type issue is still there.
We can look at the grammar and try to create alterations for every
_simple_type choice.
_simple_type: $ => choice(
prec.dynamic(-1, $._type_identifier),
$.generic_type,
$.qualified_type,
$.pointer_type,
$.struct_type,
$.interface_type,
$.array_type,
$.slice_type,
$.map_type,
$.channel_type,
$.function_type,
$.union_type,
$.negated_type,
),
I am gonna go through a few and explain my train of thought.
Nodes that start with _ are hidden from the tree because they always just wrap
a child node. This is the case here for _simple_type and _type_identifier.
They do not appear in the tree. So we have to replace them with all the choices
if we want to capture the correct values in the query. See
Hiding Rules in the docs.
Following _type_identifier in the grammar, we reach:
identifier: _ => /[_\p{XID_Start}][_\p{XID_Continue}]*/,
_type_identifier: $ => alias($.identifier, $.type_identifier),
_field_identifier: $ => alias($.identifier, $.field_identifier),
_package_identifier: $ => alias($.identifier, $.package_identifier),
From my understanding, every time we see a _type_identifier or the other two
rules and which is an identifier (basically a series of characters without a
space), we rename that node to type_identifier or the other names. Search for
aliases in the Creating Parsers to read more.
So every time we see a type_identifier node, that's just a type. This is
exactly what we have been doing. I am removing the variadic parameter path from
the example to make it more concise.
I've created a new alternation for type and one of the choices is just a
type_identifier.
(function_declaration
parameters: (parameter_list [
(parameter_declaration
name: (identifier) @func.name
type: [
(type_identifier) @param.type.identifier
])
]
))
Slice Types
Let's tackle slice_type to recognize the []byte in our example.
slice_type: $ => prec.right(seq(
'[',
']',
field('element', $._type),
)),
slice_type has a field named element with the type. The type of this field
is _type which is what we're looking for here. In other words, we're stuck
because of recursion. For now, we can just capture the text of element with a
wild card.
If I am allowed to make a prediction, we cannot really solve this problem with
queries and have to create functions that traverse the Concrete Syntax Tree
(CST) emitted by tree-sitter. E.g., we create a function that handles _type
and then call it recursively when we see it.
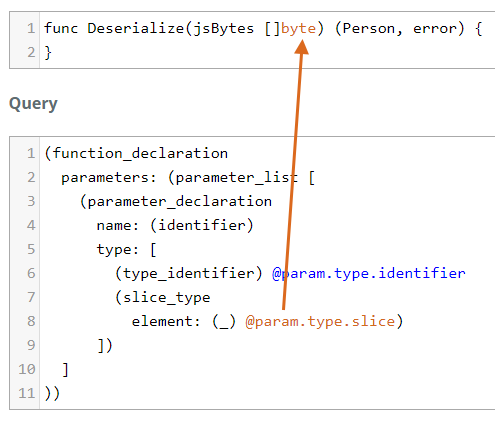
How slice_type looks in the tree.
// func Deserialize(jsBytes []byte) (Person, error) {
function_declaration
name: identifier
parameters: parameter_list // (jsBytes []byte)
parameter_declaration // jsBytes []byte
name: identifier // jsBytes
type: slice_type // []byte
element: type_identifier // byte
And our query captures the value of element with a wildcard.
(function_declaration
parameters: (parameter_list [
(parameter_declaration
name: (identifier)
type: [
(type_identifier) @param.type.identifier
(slice_type
element: (_) @param.type.slice)
])]))
Pointer Type
pointer_type is another easy example. It's just a * followed by a _type.
pointer_type: $ => prec(PREC.unary, seq('*', $._type)),
Let's add a second input parameter to our example.
// func Deserialize(a *Person, jsBytes []byte) (Person, error) {
function_declaration
name: identifier // Deserialize
parameters: parameter_list // (a *Person, jsBytes []byte)
parameter_declaration // a *Person
name: identifier // a
type: pointer_type // *Person
type_identifier // Person
parameter_declaration // jsBytes []byte
// removed
Similar to []byte, the type of a slice can be _type which brings us back to
the recursive elephant in the room that is parsing _type. Again, let's just
capture it with a wildcard and add another path to the type field.
(function_declaration
parameters: (parameter_list [
(parameter_declaration
name: (identifier)
type: [
(type_identifier) @param.type.identifier
(slice_type
element: (_) @param.type.slice)
(pointer_type (_) @param.type.pointer)
])]))
I've removed some of the paths in the screenshot so the playground uses a better capture color for this match.

Struct Type
We can define an anonymous struct right in the parameters. Apparently, Rob Pike has given us the ability to twist ourselves into a pretzel like this:
func testStructType(person struct {
name string
score int
}) int {
return person.score
}
func main() {
person := struct {
name string
score int
}{"John", 10}
fmt.Println(testStructType(person)) // 10
}
tree-sitter creates this tree:
// removed new lines in the comments.
parameter_declaration // person struct { name string score int }
name: identifier // person
type: struct_type // struct { name string score int }
field_declaration_list // { name string score int }
field_declaration // name string
name: field_identifier // name
type: type_identifier // string
field_declaration // score int
name: field_identifier // score
type: type_identifier // int
Guess what? The type inside the field_declaration is a _type. Har har! OK,
another wildcard.
(function_declaration
parameters: (parameter_list [
(parameter_declaration
name: (identifier)
type: [
(struct_type
(field_declaration_list
(field_declaration
type: (_) @param.type.struct.field)))
])]))
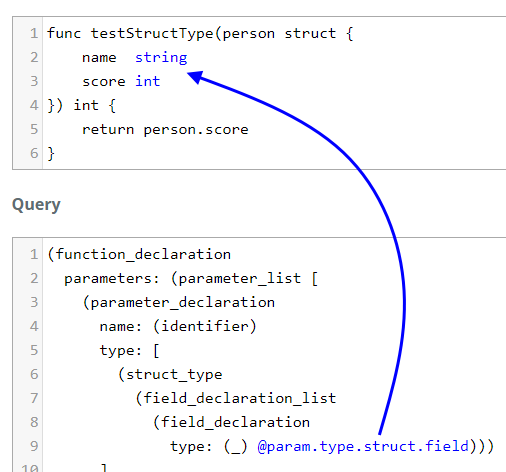
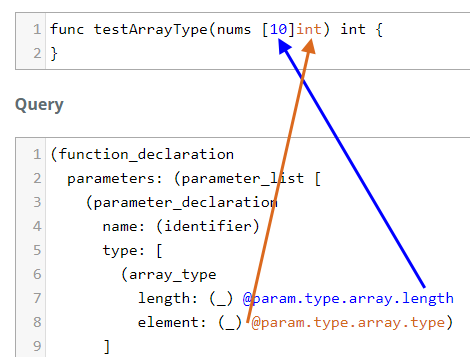
Array Type
array_type is similar. It has a length and an element as defined in the
grammar.
array_type: $ => prec.right(seq(
'[',
field('length', $._expression),
']',
field('element', $._type),
)),
Both are cans of worms to parse because they can be of recursive types. Isn't life fun?
tree-sitter will parse a sample array type input like this:
// func testArrayType(nums [10]int) int {
// removed parent nodes.
parameters: parameter_list // (nums [10]int)
parameter_declaration // nums [10]int
name: identifier // nums
type: array_type // [10]int
length: int_literal // 10
element: type_identifier // int
We will use wildcards to capture both length and type.
(function_declaration
parameters: (parameter_list [
(parameter_declaration
name: (identifier)
type: [
(array_type
length: (_) @param.type.array.length
element: (_) @param.type.array.type)
])]))
And the list goes on and on. We can add other things like maps. In the end, I ended up with this monstrosity (which is still incomplete).
(function_declaration
name: (identifier) @func.name
parameters: (parameter_list [
(parameter_declaration
name: (identifier) @param.name
type: [
(type_identifier) @param.type.identifier
(slice_type
element: (_) @param.type.slice)
(pointer_type (_) @param.type.pointer)
(struct_type
(field_declaration_list
(field_declaration
type: (_) @param.type.struct.field)))
(array_type
length: (_) @param.type.array.length
element: (_) @param.type.array.type)
(qualified_type
package: (package_identifier) @param.type.package
name: (type_identifier) @param.type.package.type)
(map_type
key: (_) @param.type.map.key
value: (_) @param.type.map.value)
(channel_type
value: (_) @param.type.channel.type)
])
(variadic_parameter_declaration
name: (identifier) @variadic.param.name
type: (_) @variadic.param.type)
]
))
Function Return Values
Return values are very similar. It's in the result field in the grammar.
function_declaration: $ => prec.right(1, seq(
'func',
field('name', $.identifier),
field('type_parameters', optional($.type_parameter_list)),
field('parameters', $.parameter_list),
field('result', optional(choice($.parameter_list, $._simple_type))), // <--- HERE
field('body', optional($.block)),
)),
- It's optional. Functions don't have to have return values.
func noReturnValue() { //... }.
- The result can be a
_simple_type.- This is the huge list we saw before.
- The result can be a list of parameters. They are called named return values.
- E.g.,
func named ReturnValues() (a int) { //... }.
- E.g.,
Basically, the return value can be a list of types or a list of parameters just like we saw in input.
Let's do a simple example. Note tree-sitter doesn't really know the types of
out, err in out, err := Deserialize(a, b). In the real world, we need more
information by reviewing the function declaration.
Let's make something up.
type Person struct {
Name string
}
// Convert JSON text to a Person object.
func Deserialize(jsBytes []byte) (Person, error) {
var p Person
err := json.Unmarshal(jsBytes, &p)
if err != nil {
return p, err
}
return p, nil
}
We can get this tree from the playground:
function_declaration
name: identifier // Deserialize
parameters: parameter_list // (jsBytes []byte)
parameter_declaration // jsBytes []byte
name: identifier // jsBytes
type: slice_type // []byte
element: type_identifier // byte
result: parameter_list // (Person, error)
parameter_declaration // Person
type: type_identifier // Person
parameter_declaration // error
type: type_identifier // error
body: block // function body
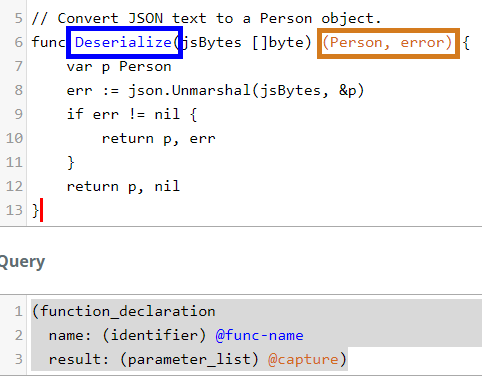
Let's build it step by step. First, we want to capture the name and result in
the function_declaration.
(function_declaration
name: (identifier) @func-name
result: (parameter_list) @capture)
See how the playground has helpfully colored the captures.
Then we continue into parameter_declaration. Note how it's still inside the
parameter_list parenthesis.
(function_declaration
name: (identifier) @func-name
result: (parameter_list
(parameter_declaration) @capture))
And then we go into the type field which is a type_identifier.
(function_declaration
name: (identifier) @func-name
result: (parameter_list
(parameter_declaration
type: (type_identifier) @return-type)))
The @return-type part only captures Person and error.
Go also supports named return parameters. It creates variables that we can use
in code and allows us to just specify return (called a naked return) which
returns the values of these variables. Personally, I don't like naked returns.
// Convert JSON text to a Person object.
func Deserialize(jsBytes []byte) (p Person, err error) {
// I know we can just return json.Unmarshal directly here, but bear with me.
err = json.Unmarshal(jsBytes, &p)
if err != nil {
return p, err // or just `return`
}
return p, nil // or just `return`
}
The resulting tree is not that different and the query works because we're
skipping the optional name child for parameter_declaration.
result: parameter_list // (p Person, err error)
parameter_declaration // p Person
name: identifier // p
type: type_identifier // Person
parameter_declaration // err error
name: identifier // err
type: type_identifier // error
We can see this in the node-types.json file in the Go grammar:
// stuff removed before and after
{
"type": "parameter_declaration",
"named": true,
"fields": {
"name": {
"multiple": true,
"required": false, // the `name` field is not required
"types": [
{
"type": "identifier",
"named": true
}
]
},
"type": {
"multiple": false,
"required": true, // the `type` field is required
"types": [
{
"type": "_type",
"named": true
}
}]}}
I came up with this query that captures a lot of return values, but is going to get rekt if it sees any complex types in the values. It will capture the text, but it will not understand most of them.
(function_declaration
name: (identifier) @func.name
result: [
(parameter_list
(parameter_declaration
type: (type_identifier) @return.type))
(type_identifier) @return.type
(qualified_type
package: (package_identifier) @return.type.package
name: (type_identifier) @return.type)
(pointer_type (type_identifier) @return.type)
(struct_type) @return.type
(interface_type) @return.type
(array_type
length: (_) @return.array.type.length
element: (_) @return.array.type.type) @return.type
(slice_type
element: (_) @return.slice.type.type) @return.type
(map_type
key: (_) @return.map.type.key
value: (_) @return.map.type.value) @return.type
(channel_type
value: (_) @return.channel.type.type) @return.type
(function_type) @return.type
(union_type
(_) @union.type.first "|" (_) @union.type.second ) @return.type
(negated_type) @return.type
]
)
Verdict
And the list goes on and on. We can use wildcards to hand-wave our way through the problem, but we return to the same issue, how do we capture recursive types with tree-sitter queries?
I don't know the answer. Unfortunately, there are only a few tree-sitter query tutorials on the internet. If you know the answer, please let me know.
But I think the answer must be in traversing the tree. A function that can take
a CST node of types _type and parse it with recursive calls.
Discovering Indirect Parent/Children Connections are Hard
Function call chains are useful. I did try to tackle it with Semgrep. We want to capture the parent of a function. Our example code is:
func parentFunc() {
a := child()
}
And tree-sitter will parse it into a tree.
function_declaration // func parentFunc() { a := child() }
name: identifier // parentFunc
parameters: parameter_list // ()
body: block // { a := child() }
short_var_declaration // a := child()
left: expression_list // a
identifier // a
right: expression_list // child()
call_expression // child()
function: identifier // child
arguments: argument_list // ()
Our query needs to capture every function_declaration and figure out if the
block has a call_expression.
Unfortunately, we cannot skip nodes in tree-sitter queries. Remember each query is a path and we have to define the complete path to capture anything. We can create paths for top-level functions and different scenarios. A query for our current code is:
(function_declaration
name: (identifier) @parent.name
body: (block
(short_var_declaration
right: (expression_list
(call_expression
function: (identifier) @child.name)))))
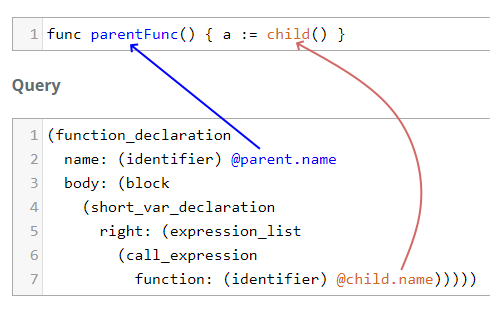
But we will fail as soon as we add any sort of complexity like
a1 := a + child() because the path is not correct. The right field of the
short_var_declaration is still an expression_list, but it's not immediately
followed by a call_expression and we have a binary_expression instead.
// a1 := a + child()
short_var_declaration // a1 := a + child()
left: expression_list // a1
identifier // a1
right: expression_list // a + child()
binary_expression // a + child()
left: identifier // a
right: call_expression // child()
function: identifier // child
arguments: argument_list // ()
We need to add a new path.
(function_declaration
name: (identifier) @parent.name
body: (block
(short_var_declaration
right: (expression_list [
(call_expression
function: (identifier) @child.name)
(binary_expression
right: (call_expression
function: (identifier) @child.name))
]
))))
This will also capture things like a2 := a1 + a + child(), but not
a2 := a1 + a / child() because it's now nested under another
binary_expression.
It will also miss things like this:
var b string
b = child2()
This requires a new path in the block which is a copy of the one for
short_var_declaration, but instead for assignment_statement.
(function_declaration
name: (identifier) @parent.name
body: (block [
(assignment_statement
right: (expression_list
(call_expression
function: (identifier) @child2.name)))
]
))
But as you can see, it will not capture b = child2() + b because we need
another path for binary_expression.
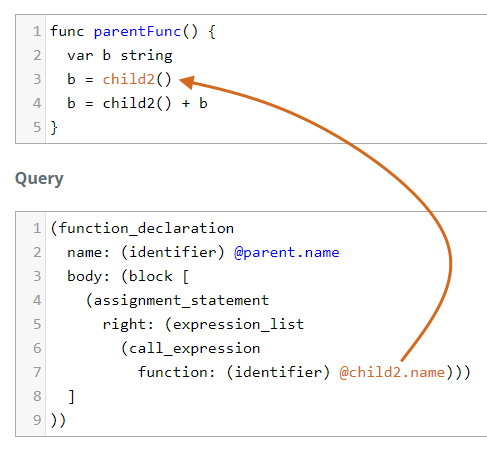
Verdict
This is not gonna work out for us. I have not tried it, but if I may make another prediction. We need to capture call_expression nodes and work out way back up traversing the tree until we reach function_declaration nodes.
Right now, I don't know how to do that yet, but I am still learning queries.
Running Queries in Rust
tree-sitter has native support for Rust Bindings (there are also bindings for many other languages thanks to FFI). I also wanted to wrestle with the Borrow Checker, so I wrote the code in Rust instead of using Go bindings.
I don't want to create "yet another tree-sitter Rust tutorial" so we're mostly gonna focus on the captures of queries we've seen so far. The results are not as neatly organized as I expected.
I've tried to make most parts abstract and there's basic error handling.
Code is in https://github.com/parsiya/knee-deep-tree-sitter.
Clone the repository and run cargo run -- 00.
Capturing Function Names
How to parse the code. Assuming src contains the source code.
fn parse_the_code(src: &str) -> Option<Tree> {
// Get the language from tree_sitter_go.
// It's Go Lang, har har!
let go_lang = tree_sitter_go::language();
let mut parser = Parser::new();
parser
.set_language(go_lang)
.expect("Error loading Go grammar");
return parser.parse(src, None);
}
Now we have a parsed tree. We can unwrap the Option.
// Parse the source.
let parsed = match parse_the_code(src) {
Some(p) => p,
None => panic!("couldn't parse the source code"),
};
Create a query.
// Query to extract function names from Go code.
let query_extract_func_names = r#"
(function_declaration
name: (identifier) @func.name)
"#;
// Compile the query.
let query = Query::new(tree_sitter_go::language(), query_extract_func_names)
.expect("couldn't parse the query");
Create a query cursor and use it iterate through the matches.
let mut cursor = QueryCursor::new();
let query_matches = cursor.matches(&query, parsed_tree.root_node(), src.as_bytes());
Each capture has an index (starting from zero). We can either get a capture's
index by name like this (note we should not include the @):
let func_name_index = query
.capture_index_for_name("func.name")
.expect("couldn't find capture index for `func.name`");
Or we can get a string slice where each capture name's position in the slice is its index in the query.
let capture_names = query.capture_names();
// capture_names[0] == func.name
Now we can iterate through the matches. Each match is a set of captures and a path in the query.
for one_match in query_matches {
for capture in one_match
.captures
.iter()
.filter(|c| c.index == func_name_index) // Not useful here, but we can filter by capture index
{
println!("{}", node_string(capture.node, src));
}
}
tree-sitter nodes don't include the actual text. It only has the location of the text in the source code. So I created a couple of helper functions to extract the text from the source and return it.
/// Extract the text of tree-sitter captured node from source.
fn node_text(node: tree_sitter::Node, src: &str) -> String {
return src[node.start_byte()..node.end_byte()].to_string();
}
/// Return the node information as a pretty string.
pub(crate) fn node_string(node: tree_sitter::Node, src: &str) -> String {
return format!(
"Text: {} - Kind: {} - sexp: {}",
node_text(node, src),
node.kind(),
node.to_sexp()
);
}
to_sexp() converts the node and its children to an S-expression. This is the
tree we see in the playground. They are helpful for creating queries that
capture specific nodes.
Bonus idea: Use this output to automatically create queries to capture specific parts of nodes from a previous capture.
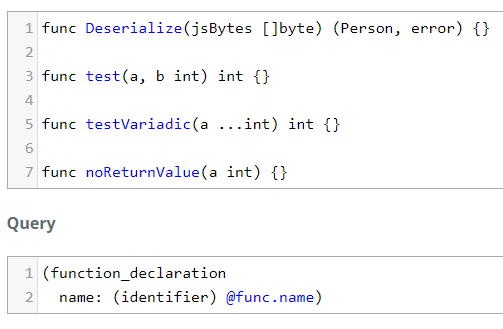
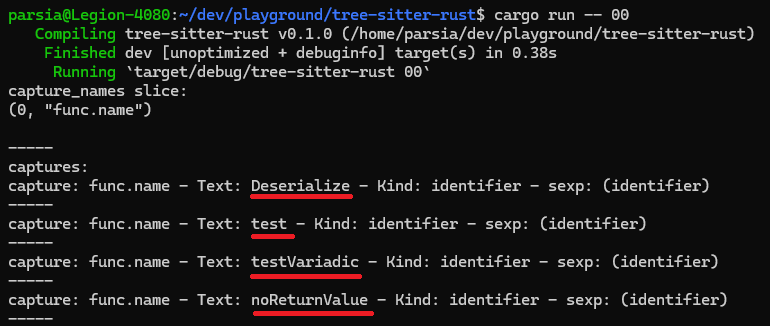
If we run it on the following code (ignore that it's not buildable code), we can grab the function names.
func Deserialize(jsBytes []byte) (Person, error) {}
func test(a, b int) int {}
func testVariadic(a ...int) int {}
func noReturnValue(a int) {}
We can see the captures in the playground.
And also by running the code with cargo run -- 00.
Capturing Function Parameters
Run cargo run -- 01. We're using the same query from before and it looks like
we're capturing everything we had before.
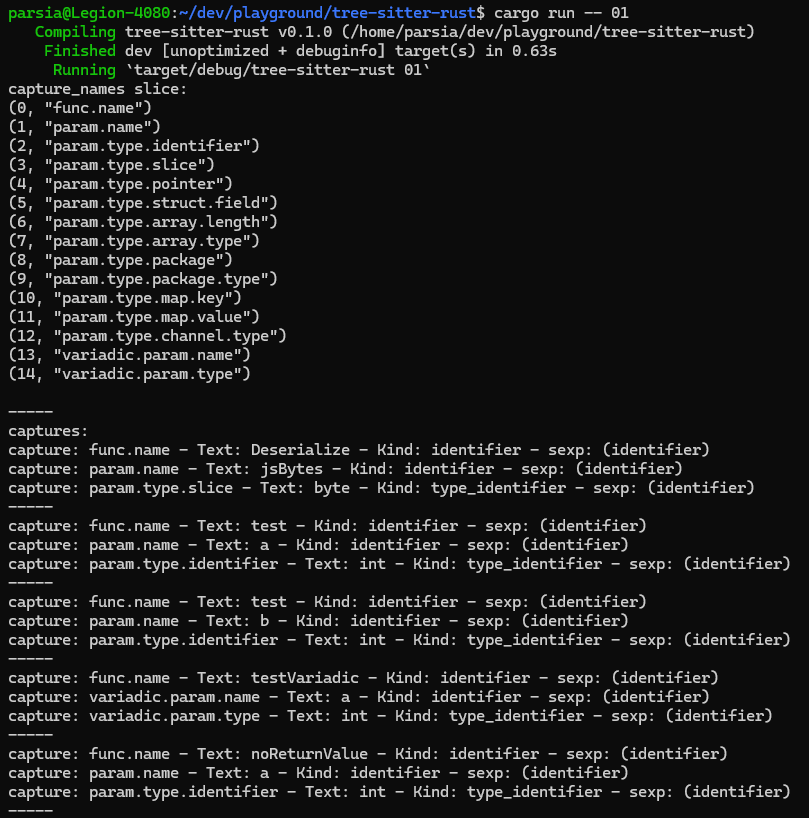
As a welcome side effect, our query is capturing the correct type for a in
(a, b int) because it's capturing the first type after its node which is the
correct type. Remember how the tree looked like. We're capturing a and the
first type_identifier sibling.
function_declaration
name: identifier
parameters: parameter_list // (a, b int)
parameter_declaration // a, b int
name: identifier // a
name: identifier // b
type: type_identifier // int
Capturing Return Values
We can also run the query to capture return values. cargo run -- 02. Here's
some of the output.
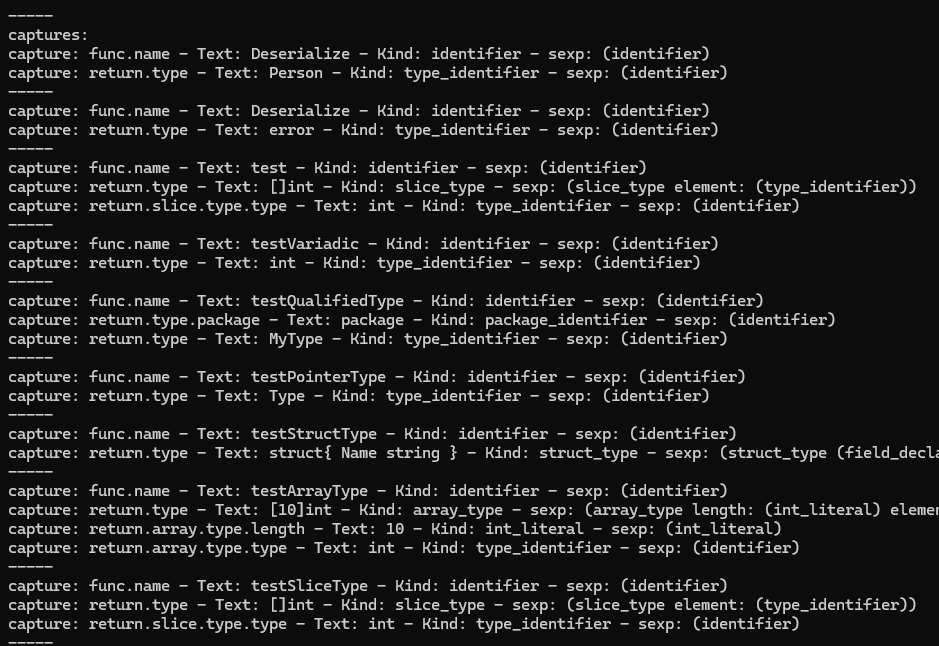
Combining all of these together, we might be able to recreate the function signature with all the extracted knowledge. As I've already said, complex types are gonna destroy the queries.
Some Pitfalls
Crate Versions
Use the version of the tree-sitter crate that is compatible with the generated parser. E.g., at the time of writing, the current version of tree-sitter-go crate (0.20) requires the tree-sitter between 0.20 and 0.21. Check the cargo.toml file.
[dependencies]
tree-sitter = ">= 0.20, < 0.21"
If you use tree-sitter 0.21 (the current version at the time of writing) in your cargo file like this, you will have errors.
[dependencies]
tree-sitter = "0.21.0" # must use 0.20.0
tree-sitter-go = "0.20.0"
Captures and Paths
A match is a complete path. If a path is valid, then all captures are populated or have some value. Captures grouped together in a match are part of the same path.
Add alternate paths with [ ]. I still have not found anything for the "lack of
a node." This is useful for things like capturing functions without return
values.
Borrow Checker
No Rust post is complete without complaining about the borrow checker.
What Did We Learn Here Today?
We learned how to write tree-sitter queries to extract info about Go functions. Learned how to use the tree-sitter playground. And how to run the queries in Rust. More importantly, we tried to tackle some real problems and found the limitations of tree-sitter queries.
In the next step, I will try to solve the same problems by traversing the CST. I am excited to see if I can combine queries and tree traversing. To identify specific nodes with queries and then pass them to functions to go through their children (or parents) to extract more information.